SRPO: Enhancing Multimodal LLM Reasoning via Reflection-Aware Reinforcement Learning
A novel framework that enhances the reasoning capabilities of multimodal large language models
† Equal Contribution
Abstract
Multimodal large language models (MLLMs) have shown promising capabilities in reasoning tasks, yet still struggle significantly with complex problems requiring explicit self-reflection and self-correction, especially compared to their unimodal text-based counterparts. Existing reflection methods are simplistic and struggle to generate meaningful, instructive feedback, as the reasoning ability and knowledge limits of pre-trained models are largely fixed during initial training. To overcome these challenges, we propose multimodal Self-Reflection enhanced reasoning with Group Relative Policy Optimization SRPO, a two-stage reflection-aware reinforcement learning (RL) framework explicitly designed to enhance multimodal LLM reasoning. In the first stage, we construct a high-quality, reflection-focused dataset under the guidance of an advanced MLLM, which generates reflections based on initial responses to help the policy model to learn both reasoning and self-reflection. In the second stage, we introduce a novel reward mechanism within the GRPO framework that encourages concise and cognitively meaningful reflection while avoiding redundancy. Extensive experiments across multiple multimodal reasoning benchmarks—including MathVista, MathVision, Mathverse, and MMMU-Pro—using Qwen-2.5-VL-7B and Qwen-2.5-VL-32B demonstrate that SRPO significantly outperforms state-of-the-art models, achieving notable improvements in both reasoning accuracy and reflection quality.
🧠 Algorithm Insight
SRPO (Self-Reflection enhanced Reasoning with Group Relative Policy Optimization) is a two-stage training framework that equips Multimodal Large Language Models (MLLMs) with explicit self-reflection and correction capabilities. The goal is to go beyond imitation learning by training models to diagnose, revise, and refine their reasoning paths.
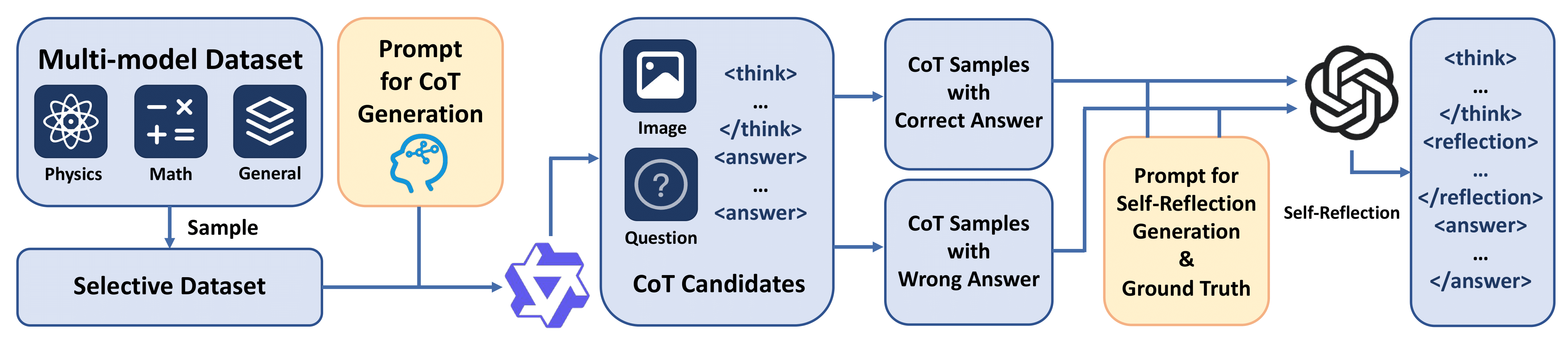
🔧 Two-Stage Reflection-Aware Training
1. Stage I – Reflection-Oriented Cold-Start Initialization (SFT)
- Data Construction: High-quality samples are curated from LLaVA-CoT, Mulberry, and MathV360K. Each training sample includes
<think>,<reflection>, and<answer>blocks. About 30% of samples are correct and refined, while 70% are flawed and revised. - Reflection Generation: A large MLLM (e.g., GPT-o4-mini) compares initial CoT outputs with ground truth to generate reflective feedback that either improves or condenses the reasoning.
- Objective: Teach models to revise initial responses and incorporate reflection in their reasoning process from the start.
2. Stage II – Reflection-Aware Reinforcement Learning
- Built on GRPO: Group Relative Policy Optimization (GRPO) estimates reward advantages within sampled response groups, enabling more stable and critic-free RL.
- Reward Design: Total reward is
Rtotal = Rtask + Rreflection, including:- Task Reward (
Rtask): Includes format validation (presence of<think>) and answer correctness. - Reflection Reward (
Rreflection): Encourages meaningful, well-structured, and efficient reflections:Ieff: Bonus for fixing wrong answers or preserving correctness.Iref: Ensures reflections follow proper formatting.flen: Smooth length-based penalty to avoid overly verbose outputs.
- Task Reward (
✅ Why It Works
- Beyond Imitation: Models are trained to improve their own flawed reasoning, not just mimic correct outputs.
- Reflection Enhances Generalization: Helps models transfer reasoning ability across disciplines like physics, biology, and chart QA.
- Reward Safety: The reward function penalizes vacuous or verbose reflections, avoiding “reward hacking.”
- Stability & Efficiency: GRPO-based reflection-aware training ensures smoother policy updates and faster convergence.
Data Samples
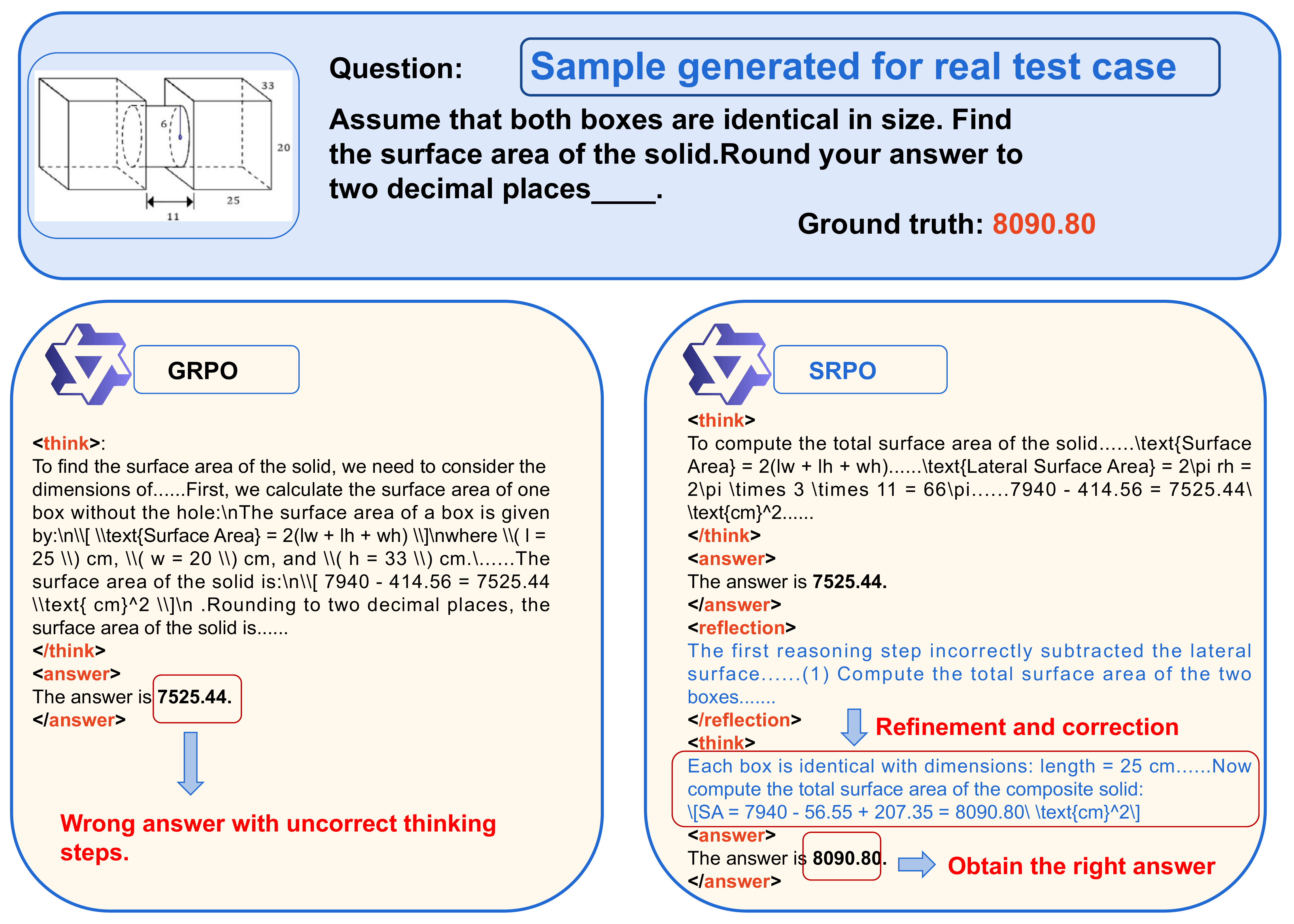
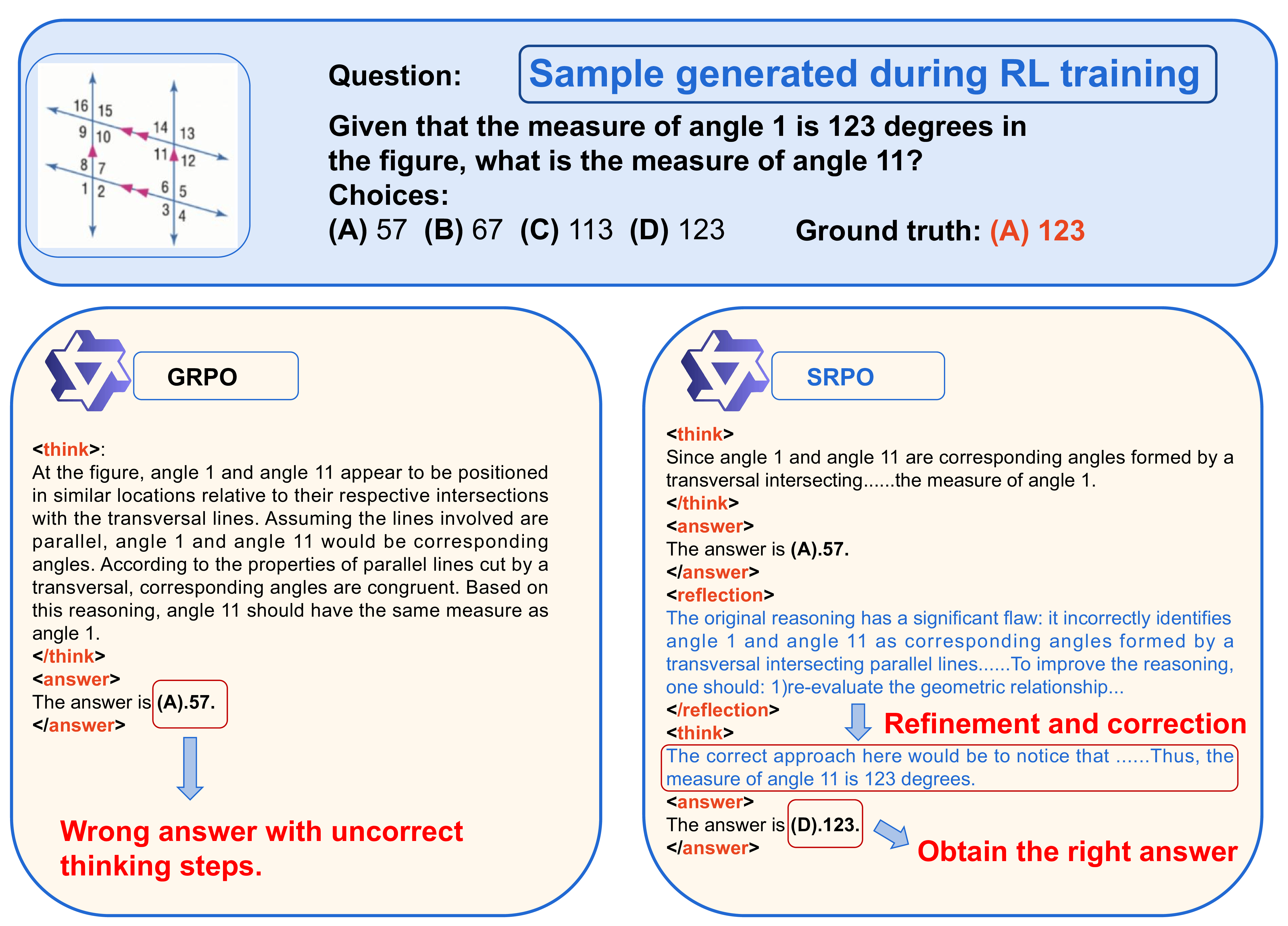

Experiments
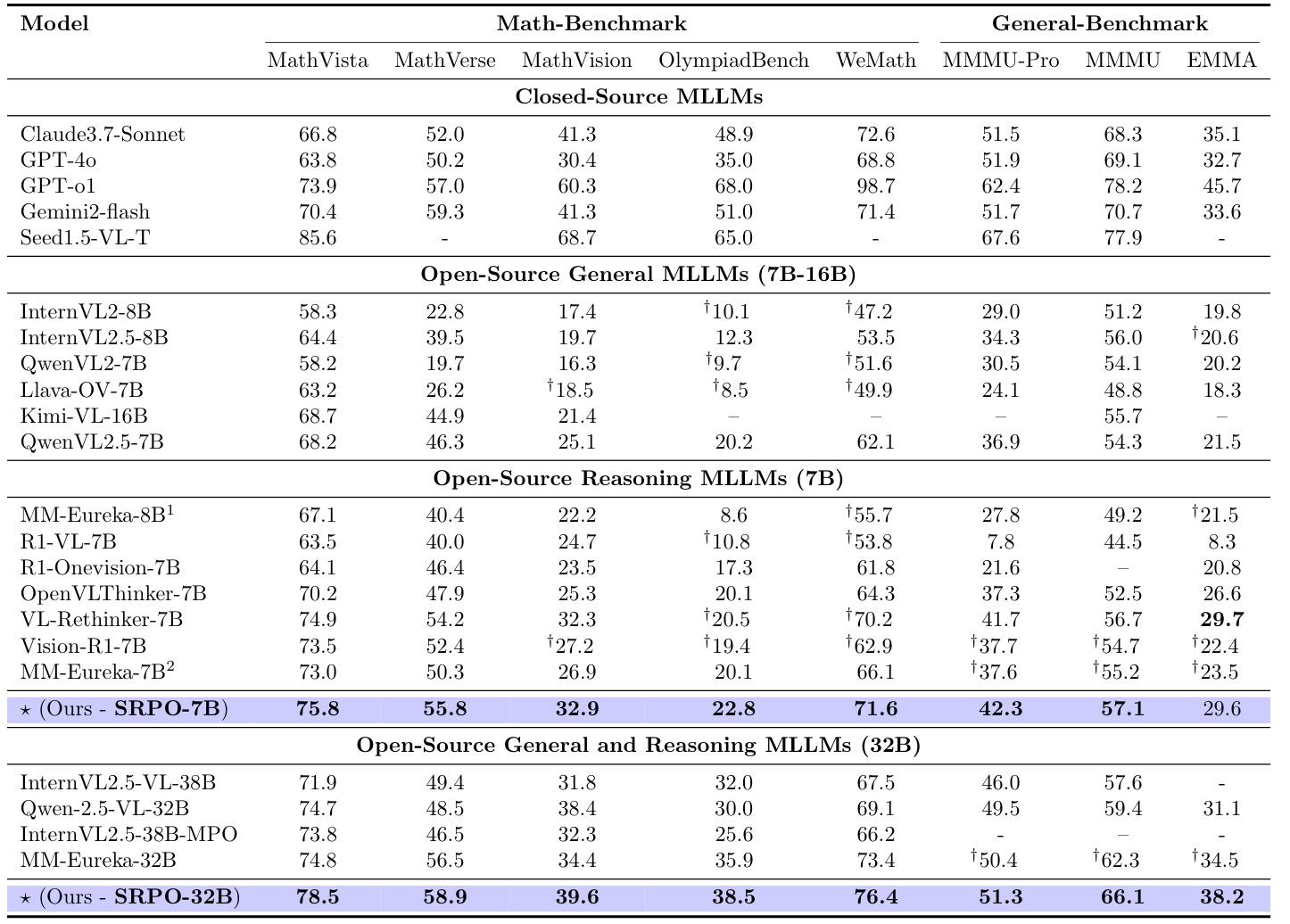
We evaluate SRPO across a wide range of multimodal reasoning benchmarks, including MathVista, MathVerse, MathVision, OlympiadBench, MMMU-Pro, EMMA, and MMK12. Our models (SRPO-7B and SRPO-32B) are compared against both closed-source systems (e.g., GPT-4o, Claude3.7, Gemini2) and open-source MLLMs (e.g., Qwen-2.5-VL, MM-Eureka, OpenVLThinker).
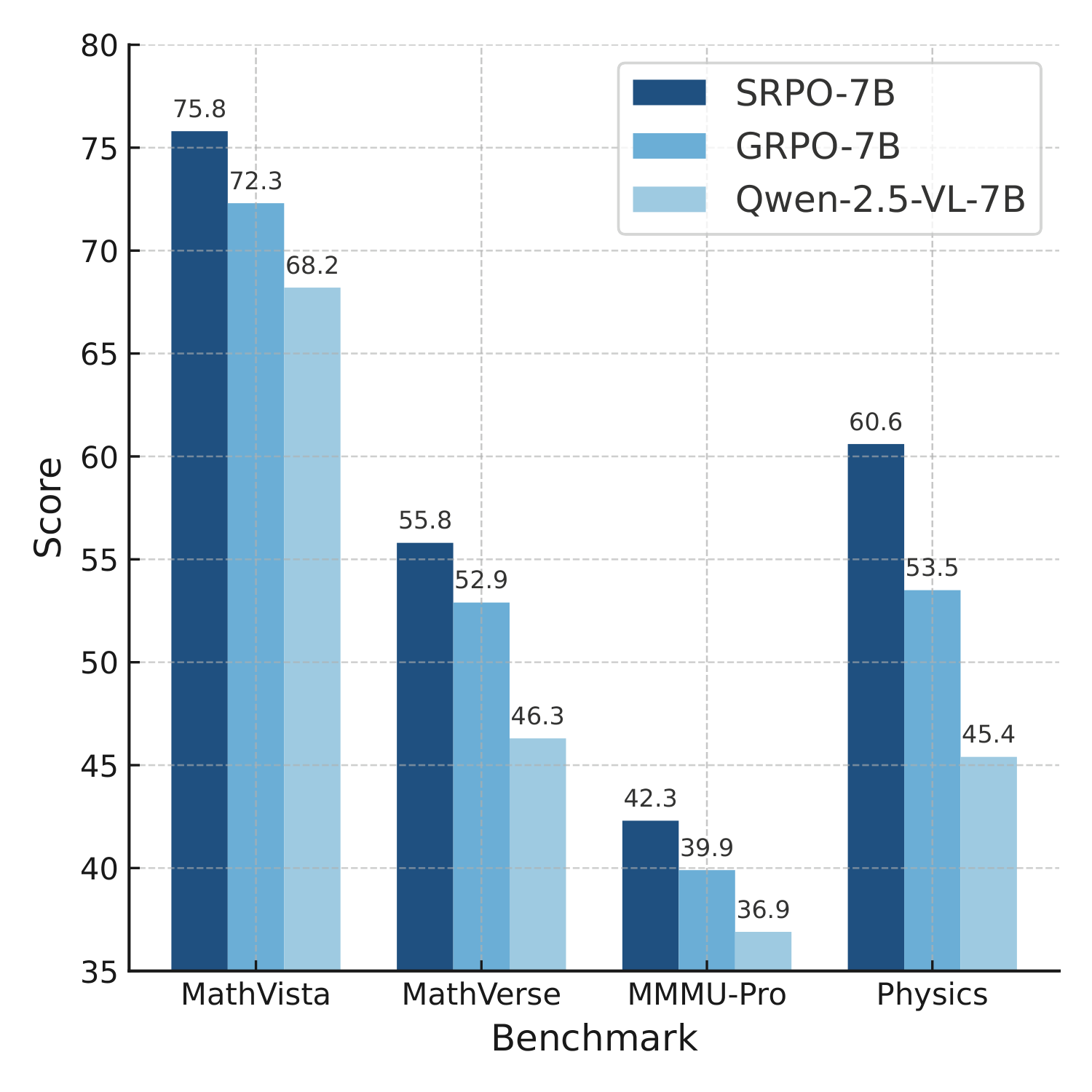
SRPO consistently outperforms previous methods across tasks, especially on reflection-sensitive benchmarks. For example, SRPO-7B surpasses VL-Rethinker-7B and MM-Eureka-7B on MathVista and MathVerse, while SRPO-32B exceeds Gemini2-flash on the EMMA general reasoning task.
We provide additional visualizations of RL training curves, including total response length, correct and incorrect response lengths, ratio clip lower, policy loss, and accuracy reward. Several key observations can be made: First, due to the explicit emphasis on self-reflection during training, SRPO consistently generates longer total responses and exhibits notably greater growth in response length compared to GRPO and SRPO without self-reflection. This is attributable to the model’s active engagement in self-reflection and subsequent correction of prior reasoning steps. Additionally, SRPO consistently achieves higher accuracy reward values than baselines, confirming that reinforcement of reflective reasoning effectively enhances the model’s reasoning capabilities. Furthermore, from the ratio clip lower and policy loss curves, we observe that SRPO—whether employing self-reflection both SFT and RL phases or solely in the RL phase—maintains stable clip lower values consistently below 0.005. This indicates that the integration of self-reflection contributes to stable policy updates with moderate gradient adjustments throughout training. Figure 2 - 8 is training dynamics of SRPO, GRPO, and SRPO w/o Self-reflection SFT
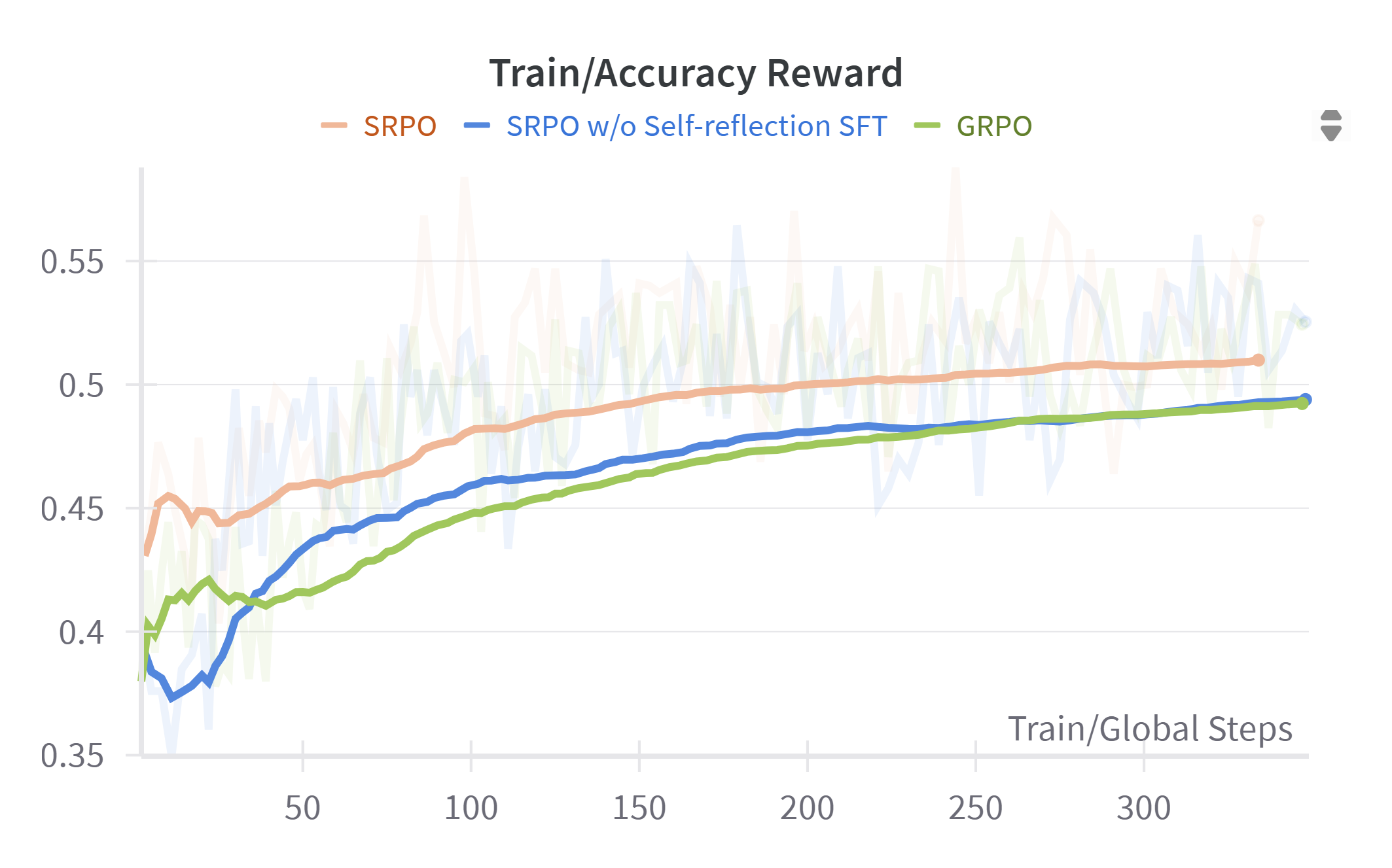
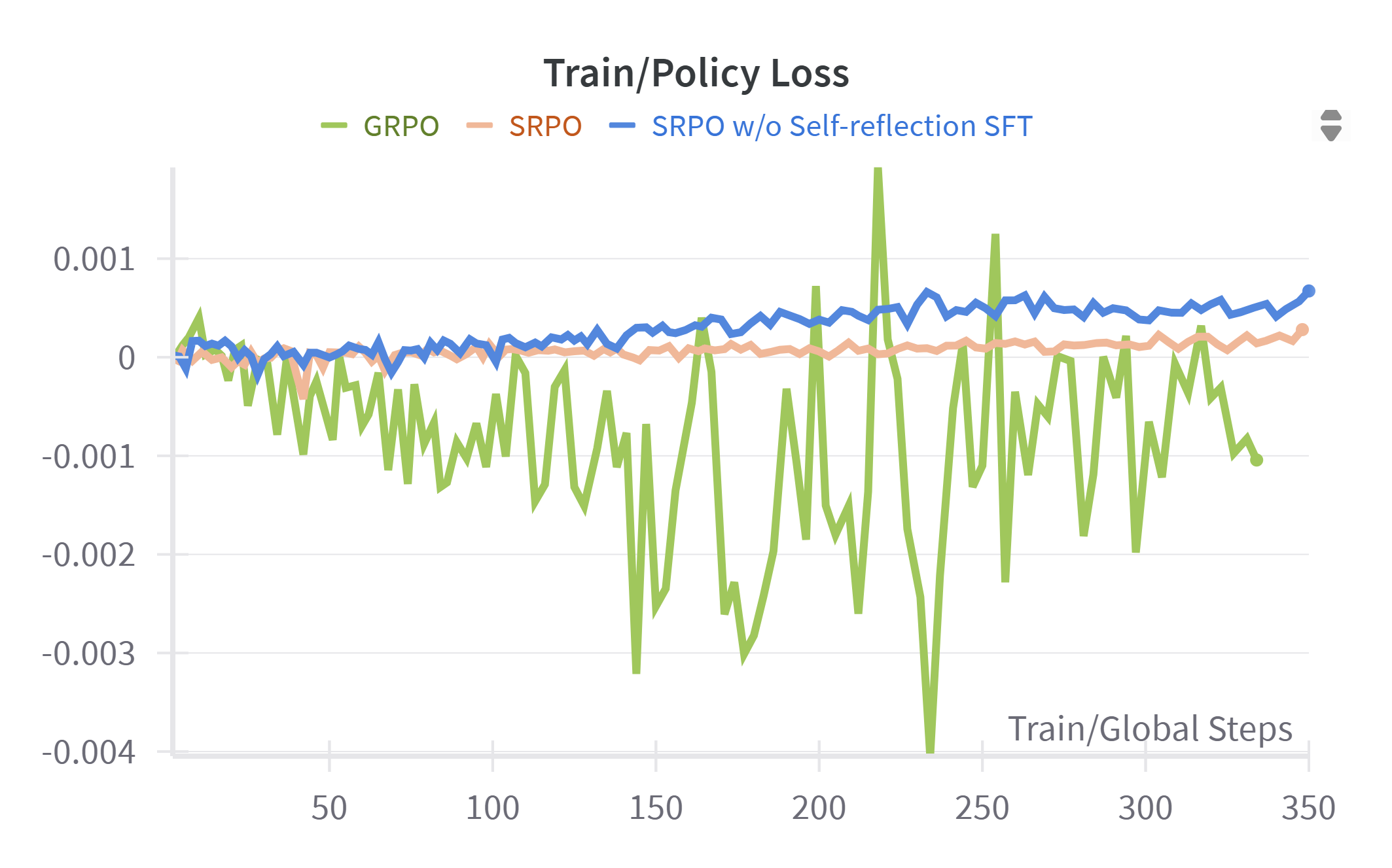
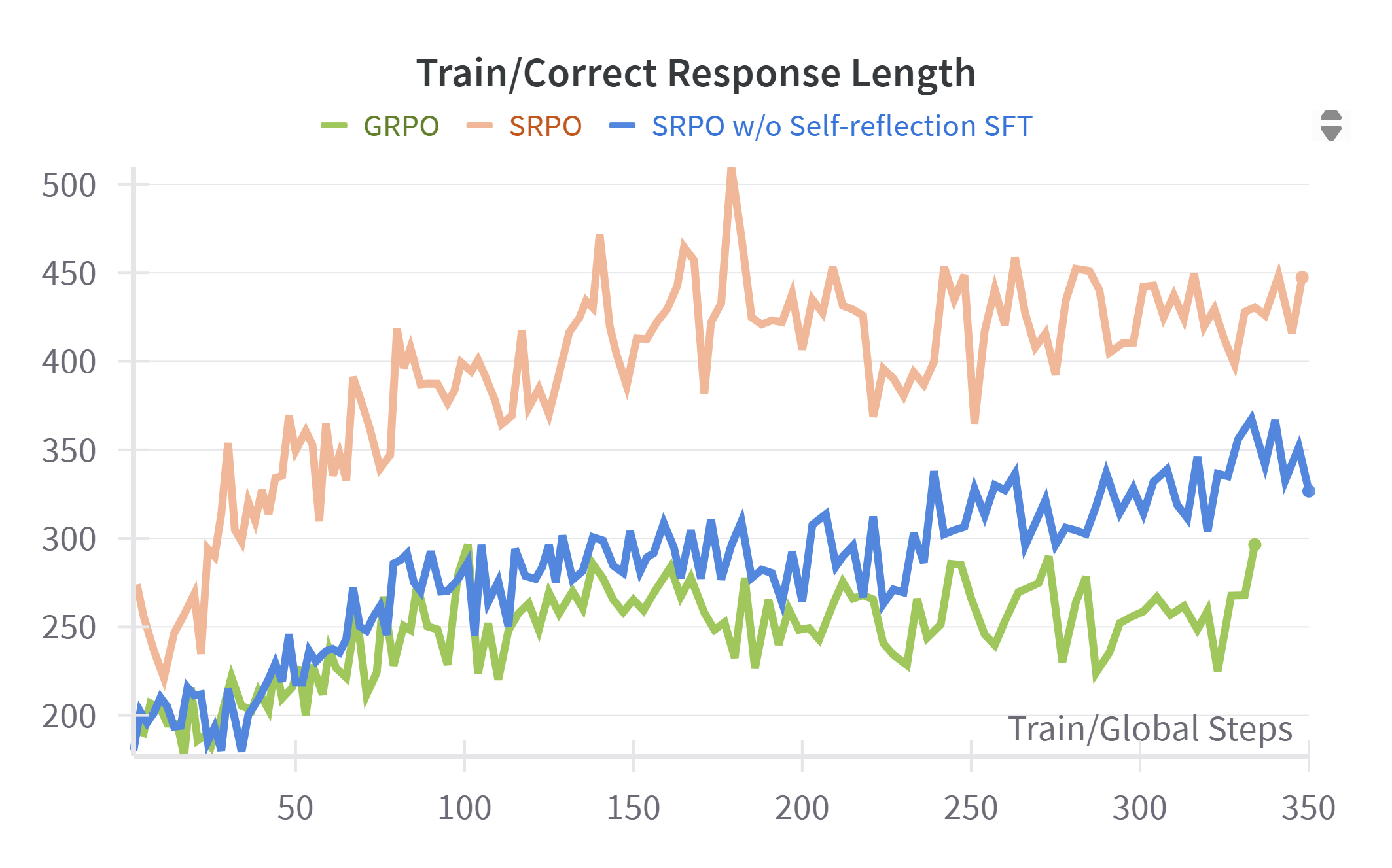
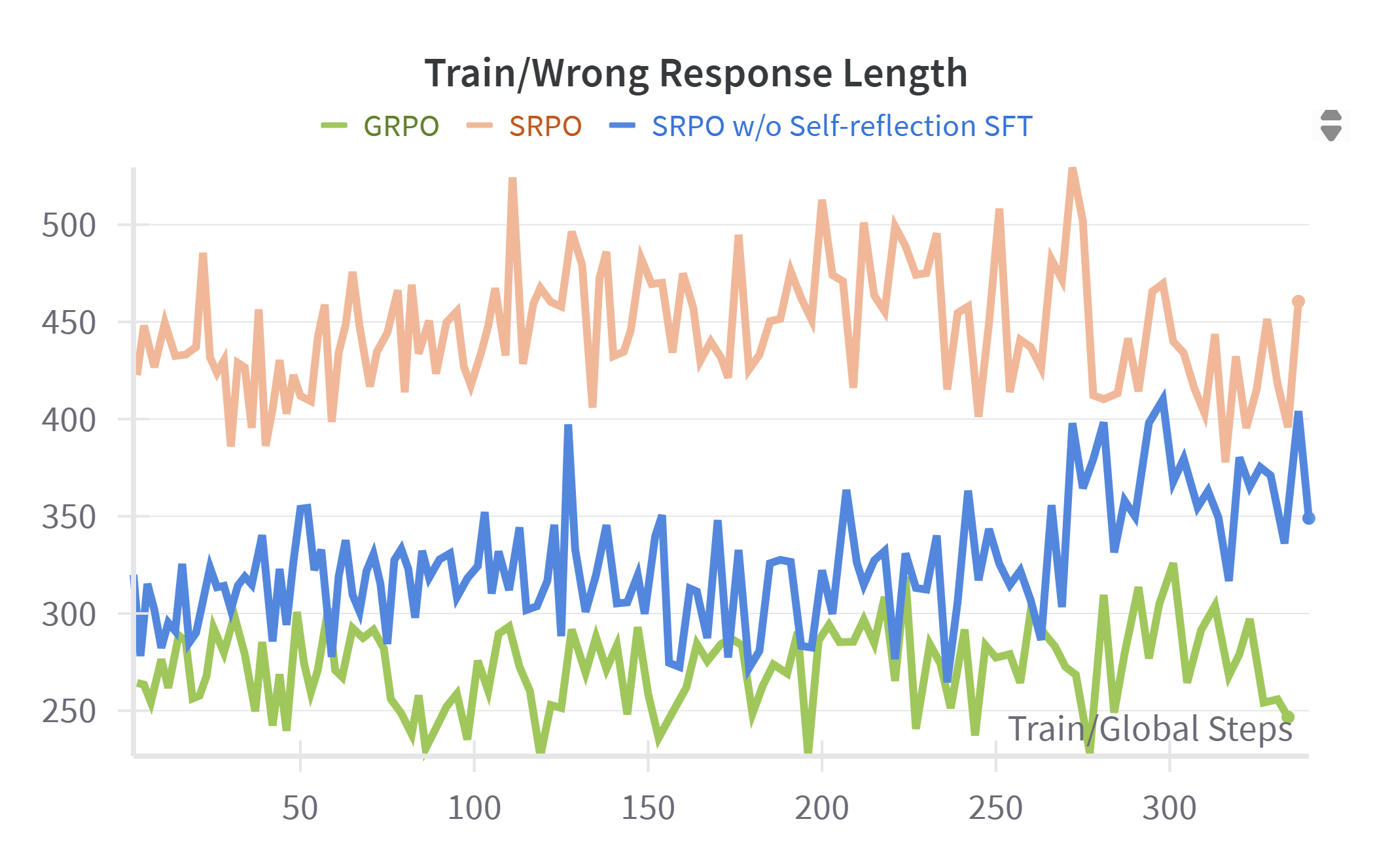
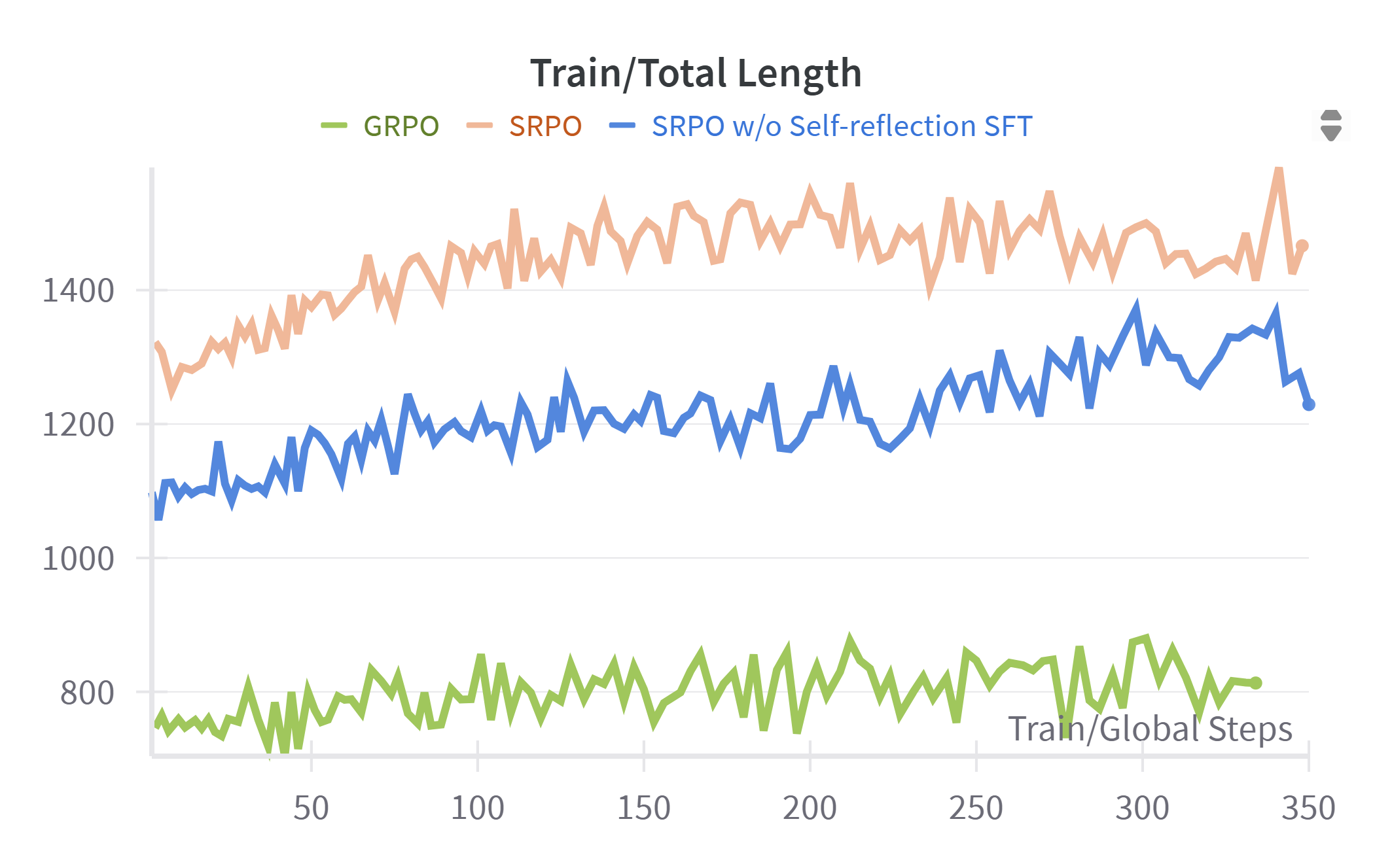
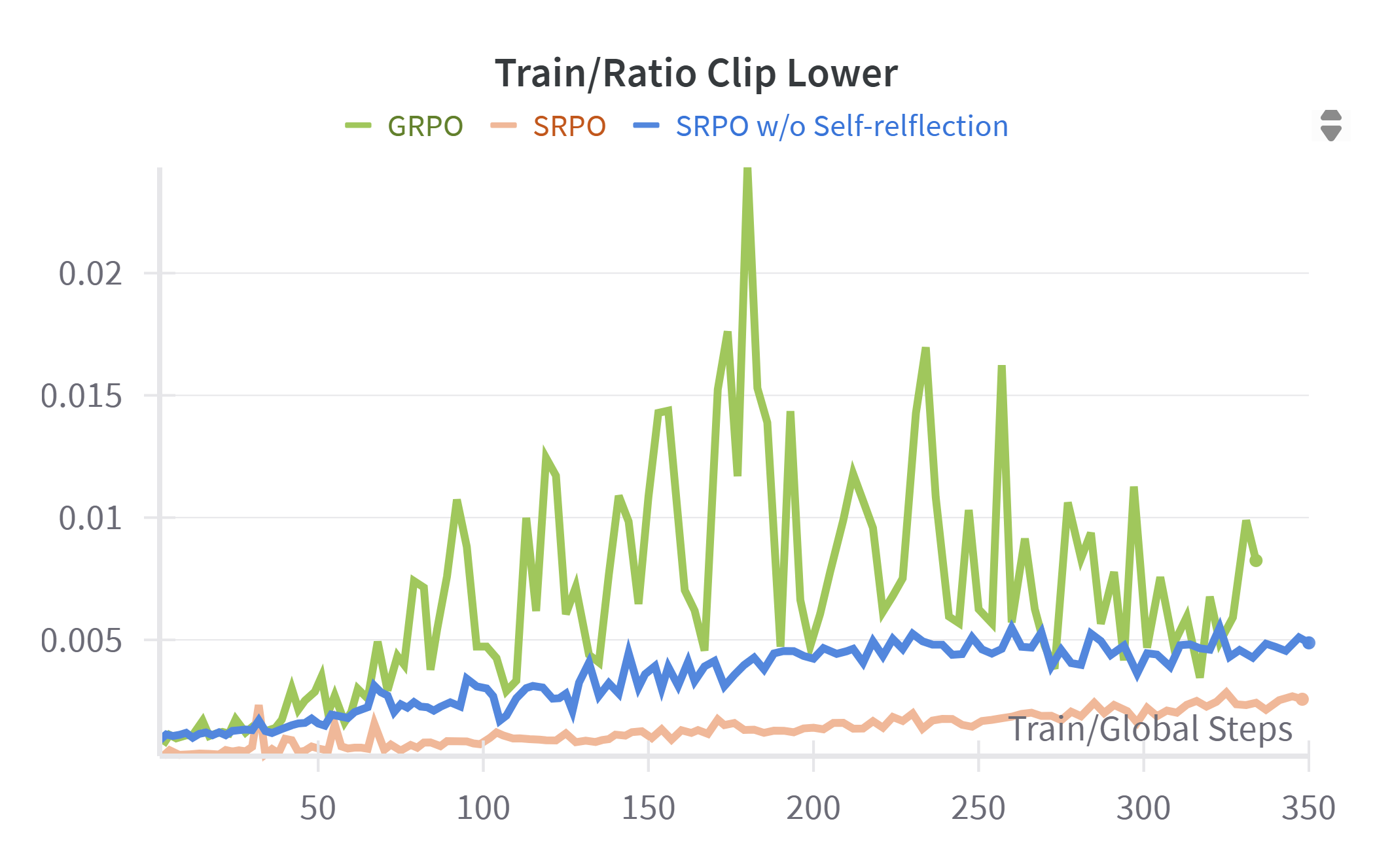
Conclusion
In this paper, we introduced SRPO, a reflection-aware reinforcement learning framework designed to enhance multimodal reasoning capabilities in mutlimodal large language models. By systematically generating high-quality reflection-focused training data and employing a novel reward mechanism that explicitly incentivizes concise and effective self-reflection, our method successfully addresses the limitations of previous approaches, including insufficient data quality and lack of self-reflective behavior for refining response. Comprehensive experiments across multiple multimodal reasoning benchmarks demonstrated the significant effectiveness of SRPO, surpassing existing state-of-the-art models in both reasoning accuracy and reflection quality. Our results highlight the critical role of reflection-driven training strategies for robust multimodal reasoning.
📖Cite Us
@misc{wan2025srpoenhancingmultimodalllm,
title={SRPO: Enhancing Multimodal LLM Reasoning via Reflection-Aware Reinforcement Learning},
author={Zhongwei Wan and Zhihao Dou and Che Liu and Yu Zhang and Dongfei Cui and Qinjian Zhao and Hui Shen and Jing Xiong and Yi Xin and Yifan Jiang and Yangfan He and Mi Zhang and Shen Yan},
year={2025},
eprint={2506.01713},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2506.01713},
}